Building a Boardgame in Azure
- Part 1 - Planning
- Part 2 - Friendships
- Part 3 - Domain Model
- Part 4 - Pipelines
- Part 5 - Migrations
About database migrations
Some time ago when I started developing software as a profession, it was quite obvious to go for your favorite programming language, and some sort of SQL-ish database to store your stuff in. Way back in my Linux time, that was Perl and MySQL or PHP and MySQL. Later that became VB and SQL Server and eventually C# and SQL Server. Now, with the cloud all around us, we carefully look at the type and kind of storage we need and pick the best possible solution for that. Is your data structured? Volatile? Does it require replication or multiple global write capabilities? Everything is possible! For this game, I went back to my good old friend called SQL Server. I’m running the database in Azure, so that means I need to provision a database server and a database in Azure.
Azure SQL
In the beginning, Azure SQL was kind of a sub-set of the real thing. You couldn’t run just any command you could run on your local SQL Server. Nowadays, Azure SQL is ahead of SQL Server in many components. It’s easy to provision and the built-in advisor is spot on helping you out with performance issues. The editions go from a cheap server allowing you to develop and test stuff for almost nothing, to full-blown SQL Server setups with huge power and capacity spending tens of thousands of your dollars a month.
Struggles with SQL Server
Now the struggles I always had with SQL Server is that you’re bound to a specific data schema. At the time we delivered Windows client software, it was fairly easy to run migration scripts when installing a new version of your software system. But what to do when something goes wrong? Nowadays we have our CI/CD pipeline, which should take care of our database migration, but how?
Pipelines
In my previous post about Pipelines, I explain how I use an Azure DevOps multi-stage pipeline, to compile and deploy my system. This would be the ideal time for me to also update the database schema and/or to execute a seed of the database.
A seed is often done when you require your database to have certain data in place prior to running the system.
Keep in mind
Always, when you create or update a database schema, make sure you’re always backward compatible. We’re going to update the database schema to a newer version just before (or at the same time) a newer version of the software system will be installed. In case one of the two fails, you may want to fall back to the previous version of your system which should not fail running on a newer database schema. In an ideal world, you would also roll the database schema version back to the previous version, but sometimes you can’t or it’s too inconvenient.
How to
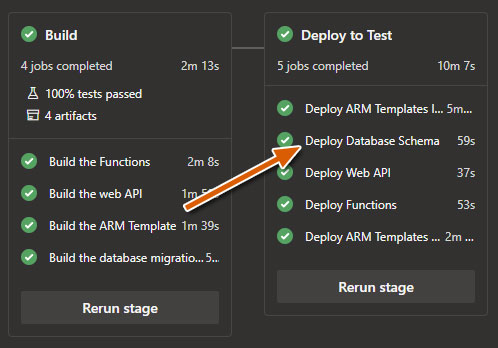 So now the idea is clear, how do you make sure this migration is executed? To do this, I added a new project to my solution just to execute the migration (and/or seed). You can add the code to your ‘default’ project, but I think this solution pollutes production code. In my opinion, a separate project just running the migration is neater. So I added a new console app to my solution.
So now the idea is clear, how do you make sure this migration is executed? To do this, I added a new project to my solution just to execute the migration (and/or seed). You can add the code to your ‘default’ project, but I think this solution pollutes production code. In my opinion, a separate project just running the migration is neater. So I added a new console app to my solution.
First I need an argument to specify the action I want to perform (e.g. Schema migration or database seed). And then I need four more arguments. For a SQL Server connection, the console app requires 4 arguments:
- Database name
- Server name (URL / IP)
- Username
- Password
Since I use a deploy-time key-vault to store secrets (like SQL Server password and stuff), all the information I need is available from within the pipeline so I’m good.
The
Microsoft.Extensions.CommandLineUtilsis a really nice NuGet package to write a CLI, it allows you to easily interpret command line arguments. I used this package for this project.
var app = new CommandLineApplication
{
Name = "KEEZ Data Migrator",
Description = "Database schema migrations for the KEEZ API"
};
app.HelpOption("-?|-h|--help");
app.Command("migrate", command =>
{
command.HelpOption("-?|-h|--help");
var databaseNameOption = command.Option("-n | --databaseName", "The name of the sql database.",
CommandOptionType.SingleValue);
var serverNameOption = command.Option("-s | --databaseServerName", "The name of the sql server.",
CommandOptionType.SingleValue);
var userNameOption = command.Option("-u | --user", "The name of database user.",
CommandOptionType.SingleValue);
var passwordOption = command.Option("-p | --password", "The password of the database user.",
CommandOptionType.SingleValue);
command.OnExecute(() =>
{
});
Now in the OnExecute, I validate if all arguments are there, of not show a hint, else execute the migration.
if (!databaseNameOption.HasValue() || !serverNameOption.HasValue() ||
!userNameOption.HasValue() || !passwordOption.HasValue())
{
app.ShowHint();
return 1;
}
To perform a database migration, you can use several different strategies. The most obvious when using C# and a SQL Server database is Entity Framework Migrations. There are however more options. When your business for example requires a DBA to maintain the database, or when you prefer to use a different ORM like LLBLGen, you may need a different approach and then the DbUp NuGet package may help you out. It allows you to execute SQL Scripts. The default setup will scan for SQL Scripts attached as an embedded resource in one of your code libraries and executes each and every SQL Script it didn’t execute earlier.
As a matter of fact, I used DbUp in this game. The following code performs a database migration using DbUp:
var builder = new SqlConnectionStringBuilder
{
["Data Source"] = $"tcp:{serverNameOption.Value()}.database.windows.net,1433",
["Initial Catalog"] = databaseNameOption.Value(),
["User Id"] = $"{userNameOption.Value()}@{serverNameOption.Value()}",
["Password"] = passwordOption.Value()
};
var upgrader =
DeployChanges.To
.SqlDatabase(builder.ConnectionString)
.WithScriptsEmbeddedInAssembly(Assembly.GetExecutingAssembly())
.LogToConsole()
.Build();
var result = upgrader.PerformUpgrade();
if (!result.Successful)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine(result.Error);
Console.ResetColor();
return -1;
}
return 0;
Adjusting the pipeline
Now I need to adjust the pipeline. The first step is, that my console app needs to be compiled and published as a pipeline artifact, just like my ‘core’ system.
- job: build_migrations
displayName: Build the database migrations package
pool:
name: "Azure Pipelines"
vmImage: "windows-latest"
steps:
- task: DotNetCoreCLI@2
displayName: "Publish Data Migration Package"
inputs:
command: "publish"
projects: "$(Build.SourcesDirectory)/path-to/command-line-project.csproj"
arguments: "--configuration Release --output $(Build.ArtifactStagingDirectory)/migrations-package -r win10-x64 --self-contained false"
publishWebProjects: false
zipAfterPublish: false
- task: PublishPipelineArtifact@0
displayName: "Publish Artifact: migrations-package"
inputs:
artifactName: "migrations-package"
targetPath: "$(Build.ArtifactStagingDirectory)/migrations-package"
So now the migration system is ready to go. Then I need to adjust the release stage to add a job, migrating the database schema.
- deployment: deploy_database
displayName: "Deploy Database Schema"
environment: "Test-Anvironment"
dependsOn:
- deploy_arm_templates_incremental
pool:
name: "Azure Pipelines"
vmImage: "windows-2019"
strategy:
runOnce:
deploy:
steps:
- task: DownloadPipelineArtifact@0
displayName: "Download Artifact: migrations-package"
inputs:
artifactName: "migrations-package"
targetPath: $(System.DefaultWorkingDirectory)/migrations-package
- task: PowerShell@2
displayName: "Update Database"
inputs:
targetType: "inline"
failOnStderr: true
script: |
Write-Host "Executing command: $(System.DefaultWorkingDirectory)\migrations-package\path-to\command-line-project.exe migrate"
$(System.DefaultWorkingDirectory)\migrations-package\path-to\command-line-project.exe migrate -n "database-name" -s "server-name" -u "user-name" -p "$(your-very-secret-password)"
if ($LASTEXITCODE -ne 0) {
exit $LASTEXITCODE
}
And that’s it! You’re good to go!
Conclusion
In the past, I used to do the database migration from within the ‘core system’. So for example when deploying an ASP.NET Website, run the migration from within the startup. A huge disadvantage because migrations and seeds may take a while and ASP.NET startup procedures are already a little bit slow. The other option is to use command-line arguments and call you ASP.NET app with that arguments to update the database, but once again, it pollutes the code base in my opinion.
Finally, by configuring your database migration as a job within a multi-stage pipeline, you allow the pipeline to execute the migration in parallel with other systems which is a big advantage because you can dramatically save time there. As you can see in the image above, I execute an ARM Template Incremental job, wait for that, and then execute three jobs in parallel (Update the database, Install the API App, Install Azure Functions App).
Go ahead and give it a spin!
Last modified on 2020-08-21

